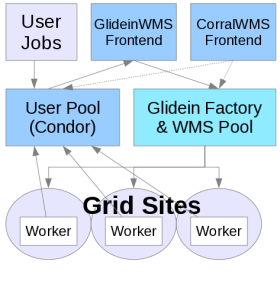
Submitting with a VO Frontend
These examples assumes you have GlideinWMS installation running and as a user you have access to submit jobs. Make sure you have sourced the correct HTCondor installation.NOTE: It is recommended that you always provide a voms proxy in the user job submission. This will allow you to run on a site whether or not gLExec is enabled. A proxy may also be required for other reasons, such as the job staging data.
The GlideinWMS environment looks almost exactly like a regular, local HTCondor pool. It just does not have any resources attached unless you ask for them; try
$ condor_statusand you can see that no glideins are connected to your local pool. The glideinWMS system will submit glideins on your behalf when they are needed. Some information may need to be specified in order for you get glideins that can run your jobs. Depending on your VO Frontend configurations, you may also have to specify additional requirements.
Submitting a simple job with no requirements
Here is a generic job that calculates Pi using the monte carlo method. First create a file called pi.py and make it executable:
#!/bin/env python
from random import *
from math import sqrt,pi
from sys import argv
inside=0
n=int(argv[1])
for i in range(0,n):
x=random()
y=random()
if sqrt(x*x+y*y)<=1:
inside+=1
pi_prime=4.0*inside/n
print pi_prime, pi-pi_prime
You can run it:
$ ./pi.py 1000000
3.1428 -0.00120734641021
The first number is the approximation of pi. The second number is how far from the real pi it is. If you repeat this, you will
see how the result changes every time.
Now, let's submit this as a HTCondor job. Because we are going to run this multiple times (100), it will actually be a bunch of jobs. These jobs should run everywhere so we won't need to specify any additional requirements. Create the submit file and call it myjob.sh:
Universe = vanilla
Executable = pi.py
Arguments = 10000000
Requirements = (Arch=!="")
Log = job.$(Cluster).log
Output = job.$(Cluster).$(Process).out
Error = job.$(Cluster).$(Process).err
should_transfer_files = YES
when_to_transfer_output = ON_EXIT
Queue 100
Next submit the job:
$ condor_submit myjob.shThe VO Frontend is monitoring the job queue and user collector. When it sees your jobs and that there are no glideins, it will ask the Factory to provide some. Once the glideins start and contact your user collector, you can see them by running
$ condor_statusHTCondor will match your jobs to the glideins and the jobs will then run. You can monitor the status of your user jobs by running
$ condor_qOnce the jobs finish, you can view the output in the job.$(Cluster).$(Process).out files.
Understanding where jobs are running
While your jobs can run everywhere, you may still want to know where they actually ran; possibly becuase you want to know who to thank for the CPUs you were consuming, or to debug problems you had with your program.To do this, we add some additional attributes to the submit file:
Universe = vanilla
Executable = pi.py
Arguments = 50000000
Requirements = (Arch=!="")
Log = job.$(Cluster).log
Output = job.$(Cluster).$(Process).out
Error = job.$(Cluster).$(Process).err
should_transfer_files = YES
when_to_transfer_output = ON_EXIT
+JOB_Site = "$$(GLIDEIN_Site:Unknown)"
+JOB_Gatekeeper = "$$(GLIDEIN_Gatekeeper:Unknown)"
Queue 100
These additional attributes in the job are used by the VO Frontend to find sites that match these requirements. HTCondor also uses them to
match your jobs to the right glideins.
Now submit the job cluster as before. You can monitor the running jobs with:
$ condor_q `id -un` -const 'JobStatus==2' -format '%d.' ClusterId -format '%d ' ProcId -format '%s\n' MATCH_EXP_JOB_Site
Submitting with a Corral Frontend
This example assumes you have GlideinWMS installation running and as a user you have access to submit jobs. You must also have Corral and Pegasus installed with the input data files.NOTE: It is recommended that you always provide a voms proxy in the user job submission. This will allow you to run on a site whether or not gLExec is enabled. A proxy may also be required for other reasons, such as the job staging data.
Using Pegasus with GlideinWMS and Corral
For our example, the workflow is generated by Pegasus. Because of the grouping Pegasus does, there will not be a huge number of jobs but the workflow fans out quickly, then down to a single job (the background model) and then fans out again.The example workflow is using NASA IPAC Montage to combine many images into a single image, for example using those taken by the NASA space telescopes. The workflow takes in the inputs for a specified area and does the following:
- reprojects the images
- checks how they overlap
- runs a background model to match up the images
- applies background diffs
- and then tiles the images together
To use Corral, you will need a long running grid proxy that will stay valid for the length of the workflow.
To begin, we create a config file. firefly.xml, that contains the information needed to get glideins from a site. This includes an abstract description of the workflow, a couple of catalogs describing files and site information.
<corral-request>
<local-resource-manager type="condor">
<main-collector>cwms-corral.isi.edu:9620</main-collector>
<job-owner>testuser</job-owner>
<!-- alias for the site - make this match your Pegasus site catalog -->
<pegasus-site-name>Firefly</pegasus-site-name>
</local-resource-manager>
<remote-resource type="glideinwms">
<!-- get these values from the factory admin -->
<factory-host>cwms-factory.isi.edu</factory-host>
<entry-name>UNL</entry-name>
<security-name>corral_frontend</security-name>
<security-class>corral003</security-class>
<!-- project is required when running on TeraGrid -->
<project-id>TG-...</project-id>
<min-slots>0</min-slots>
<max-slots>1000</max-slots>
<!-- number of glideins to submit as one gram job -->
<chunk-size>1</chunk-size>
<max-job-walltime>600</max-job-walltime>
<!-- List of entries for the grid-mapfile for the glideins. Include the daemon
certificate of the collector, and the certificate of the user submitting the glideins. -->
<grid-map>
<entry>"/DC=org/DC=doegrids/OU=People/CN=TestUser 001" condor001</entry>
<entry>"/DC=org/DC=doegrids/OU=Services/CN=cmws-corral.isi.edu" condor002</entry>
</grid-map>
</remote-resource>
</corral-request>
One you have created the request XML file you can submit it to Corral. First, create a provisioning request:
$ corral create-provisioner -h cwms-corral.isi.edu -f firefly.xmlYou can also list your provisioners:
$ corral list-provisioners -h cwms-corral.isi.eduOr remove a provisioner:
$ corral remove-provisioner -h cwms-corral.isi.eduFinally, start the workflow:
$ ./submit
Pegasus then maps the workflow to the resource and generates the DAG and all the needed submit files. A timestamped work directory has been
generated, and inside of that, there is another directory starting with your username. Move to that directory:
$ cd 2010-12-08_003519/
$ cd rynge.2010-12-08_003519
We can see how many submit files we have:
$ ls *.sub | wc -l
300
Just like a normal DAG, you can use condor_q -dag and condor_status to monitor your jobs. You can also use pegasus-analyze from within
that work directory, and it will give you some information on for example failed jobs:
$ pegasus-analyze
************************************Summary*************************************
Total jobs : 299 (100.00%)
# jobs succeeded : 0 (0.00%)
# jobs failed : 0 (0.00%)
# jobs unsubmitted : 298 (99.67%)
# jobs unknown : 1 (0.33%)
*****************************Unknown jobs' details******************************
=======================create_dir_montage_0_GridUNESP_SP========================
last state: SUBMIT
site: GridUNESP_SP
submit file: /home/rynge/exercises-tests/glideinwms-exercises/montage/2010-12-08_003840/rynge.2010-12-08_003840/create_dir_montage_0_GridUNESP_SP.sub
output file: /home/rynge/exercises-tests/glideinwms-exercises/montage/2010-12-08_003840/rynge.2010-12-08_003840/create_dir_montage_0_GridUNESP_SP.out
error file: /home/rynge/exercises-tests/glideinwms-exercises/montage/2010-12-08_003840/rynge.2010-12-08_003840/create_dir_montage_0_GridUNESP_SP.err
---------------------create_dir_montage_0_GridUNESP_SP.out----------------------
---------------------create_dir_montage_0_GridUNESP_SP.err----------------------
**************************************Done**************************************
Unknown in this case is a good thing. It just means that Pegasus does not know much about the job yet as it hasn't started.
We can also view a graph of the provisioning in real time in the monitoring. As the workflow fans out with lots of jobs, you can see how more glideins are requested. Once the glideins connect to the local pool, the jobs are matched and start running. As time goes on, no new glideins are requested because the glideins are reused for other jobs waiting in the queue.
Once the workflow is done, you should have a couple of FITS files and a JPG in the directory one level up. Open the JPG in an image viewer to see the result.
Screencast Tutorial for the NASA IPAC Montage Example
Additional resources
If you need help debugging issues with running jobs, see our Frontend troubleshooting guide.