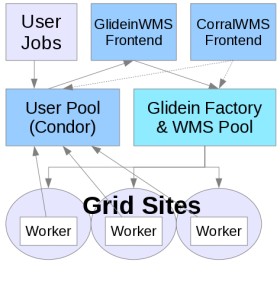
WMS Factory
- Overview
- Details
- Configuration
- Design
- Monitoring
- Troubleshooting
Factory Troubleshooting
Jump to:
If you installed the RPM distribution, files and commands differ a bit, see the Factory OSG RPM guide.
Factory does not submit glideins corresponding to your job
Symptoms:User job stays idle and there are no glideins submitted to the glidein queue that correspond to your job.However, the VO Frontend does detect the job and attempts to advertise to the Factory
Useful Files: GLIDEINWMS_GFACTORY_HOME/<entry>/log
Debugging Steps:
Once the Frontend identifies potential entry points that can run your job, it will reflect this information in the glideclient ClassAd in the WMS Pool collector for that corresponding entry point. You can find this information by running “condor_status -any -pool <wms collector>” Glidein factory looks up the glideclient ClassAd, queries the wms collector to find out distribution of existing glideins in the glidein queues and submits additional glideins as required. Once the factory has submitted the required glideins, you can see them by querying glideins queue using command, “condor_q -g -pool <wms collector>”
If you do not see any glideins corresponding to your job,
- Check if the Factory is running. If not, start it.
- Check if the entry point is enabled in the Factory, configuration file, GLIDEINWMS_GFACTORY_HOME/glideinWMS.xml
- Check for error messages in logs located in GLIDEINWMS_GFACTORY_HOME/<entry>/log
- Look for possible error messages in the glideins queue (condor_schedd). Based on the actual condor scheduler, you can find scheduler logfile, SchedLog, in one of the sub directories of directory listed by “condor_config_val local_dir”
- Check security settings. The WMS factory will drop requests from the VO frontends if settings do not match correctly. There will usually be lines in the VO Frontend that useful factories exist, but the Factory logs will have warnings/errors related to security settings.
- The first line in frontend.xml must match the name in security-frontends-frontend in the Factory's GlideinWMS:
<frontend advertise_delay="5" frontend_name="exampleVO-cms-xen25-v1_0" loop_delay="60">
Must match the Factory's settings:<frontend name="exampleVO-cms-xen25" identity="vofrontend@cms-xen25.fnal.gov">
Note that the identity line must have the username that the Frontend is running as. The security_class tag in glideinWMS.xml shortly after the above line will map the user to a new local user. This must match the condor_mapfile. - Make sure to do a reconfig after you modify anything (ie):
./frontend_startup reconfig ../instance_v1_0.cfg/frontend.xml
- Whitelist error: (WARNING: Client NAME.main (secid: IDENTITY) not in white list. Skipping request). Verify that the security_name (in the Frontend config <frontend><collector><security security_name="foo">) must match the Frontend name (<frontend name="foo">) in the Factory config.
Also, if you have enabled allowed_vos for whitelist functionality, make sure this security class is listed. - Frontend not coming from a trusted source: (WARNING: Client name.main (secid: identity) is not coming from a trusted source; AuthenticatedIdentity identity@x.fnal.gov!=identity2@y.fnal.gov. Skipping for security reasons.). There is a mismatch between <frontend><collector my_identity> in the Frontend config and <frontend identity> in the Factory config. If you are running on the same machine, this can be caused if HTCondor is using filesystem (FS) authentication instead of GSI authentication.
- No mapping for security class: (WARNING: No mapping for security class Frontend of x509_proxy_0 for frontend_service-v2_4_3.main (secid: frontend_identity), skipping and trying the others). The Frontend config's proxy element security_class attribute does not match the Factory config's security_class element name attribute.
- Client provided invalid ReqEncIdentity: (Client X provided invalid ReqEncIdentity ( id1@x.fnal.gov!= id2@x.fnal.gov). Skipping for security reasons. When the VOFrontend contacts the WMS Pool collector using the Frontend configuration file's security element proxy_DN/classad_proxy attribute, the WMS Pool HTCondor uses the certs/condor_mapfile to map the VOFrontend to a name. This name identifies how the Factory knows the VOFrontend on the Factory node. This must match with the Factory configuration file's Frontend element identity attribute.
Verify that the proxy_dn in the security section of the Frontend config matches the condor_mapfile on the WMS Pool node. This identity (with machine name) should map the Frontend identity in the Factory config. Also, if you are running all services on the same machine, make sure that HTCondor is using GSI authentication and not file system (FS) authentication.
Security Overview
For a visual representation of the GSI configuration that must match, see the below:Frontend config (on host myfrontend.example.org)For a visual representation of the JWT configuration that must match, see the below:
<frontend frontend_name="frontend_service-v3_4"
<collector my_identity="frontend_identity@myfactory.example.org"
<security security_name="frontend_identity" proxy_DN=" /DC=org/DC=doegrids/OU=Services/CN=glidein/myfactory.example.org "
<credential type="grid_proxy" security_class="frontend"
Factory config (on myfactory.example.org)
<frontend name="frontend_identity" identity="frontend_identity@myfactory.example.org"
<security_class name="frontend" username="vo_cms"
CONDOR_LOCATION/certs/condor_mapfile (on both myfrontend.example.org and myfactory.example.org)
GSI " ^ \/DC\=org\/DC\=doegrids\/OU\=Services\/CN\=glidein\/myfactory\.fnal\.gov$ " frontend_identity
Frontend config (on myfrontend.example.org)An IDTOKEN with the identity "frontend_identity@myfactory.example.org" can be created via a 3 step process:
<frontend frontend_name="frontend_service-v3_4"
<collector my_identity="frontend_identity@myfactory.example.org"
<security security_name="frontend_identity"
<credential type="scitoken" security_class="frontend"
Factory config (on myfactory.example.org)
<frontend name="frontend_identity" identity="frontend_identity@myfactory.example.org"
<security_class name="frontend" username="vo_cms"
~frontend/.condor/tokens.d (on myfrontend.example.org)
# processes owned by the frontend uid need an IDTOKEN to communicate with condor processes on various machines
# for example: frontend running on host myfrontend.example.org communicating with factory on host myfactory.example.org
# with an extra HA condor collector on host mycollector.example org would need three IDTOKENS in ~frontend/.condor/tokens.d
# with the following subjects (also known as identities to some condor_token tools)
IDTOKEN 1 with subject: identity="frontend_identity@myfrontend.example.org"
IDTOKEN 2 with subject: identity="frontend_identity@myfactory.example.org"
IDTOKEN 3 with subject: identity="frontend_identity@mycollector.example.org"
- The frontend admin at myfrontend.example.org requests an IDTOKEN from the factory with condor_token_request
[root@myfrontend ~]#condor_token_request -id frontend_identity@myfactory.example.org -pool myfactory.example.org
- The factory admin approves the request
[root@myfactory ~]# condor_token_request_list AuthenticatedIdentity = "ssl@unmapped" ClientId = "myfrontend.example.org-235" PeerLocation = "131.225.152.143" RequestedIdentity = "frontend_identity@myfrontend.example.org" RequestId = "9299245" [root@fermicloud588 ~]# condor_token_request_approve -req 9299245 Request contents: RequestedIdentity = "frontend_identity@myfactory.example.org" AuthenticatedIdentity = "ssl@unmapped" PeerLocation = "131.225.152.143" ClientId = "myfrontend.example.org-235" RequestId = "9299245" To approve, please type 'yes' yes Request 9299245 approved successfully.
- The above action generates an IDTOKEN that is printed to stdout on the frontend admins screen. The frontend admin places this output in a file in directory ~frontend/.condor/tokens.d, and changes file ownership so it is owned by the frontend user.
glideins stay idle
Symptoms: glidein stays idle and do not start running.Useful Files:
GLIDEINWMS_GFACTORY_HOME/<entry>/log
GLIDEINWMS_WMSCOLLECTOR_HOME/condor_local/logs/SchedLog
GLIDEINWMS_WMSCOLLECTOR_HOME/condor_local/logs/CollectorLog
GLIDEINWMS_WMSCOLLECTOR_HOME/certs/condor_mapfile
Debugging Steps:
Once the glideins are submitted, they should start running on the remote sites. Time taken for them to enter the running state could vary based on the site, how busy the site is, priority your glideins have on the site.
If the glideins stay idle for quite some time,
- Check if the glidein has been submitted to the remote site. You can find this information either from the condor_activity log found in the GLIDEINWMS_GFACTORY_HOME/<entry>/log or by querying glideins queue using “condor_q -globus -g -pool <wms collector>”. If the glidein job was submitted to the remote site, its quite possible that it is waiting for a worker node to be available to run it.
- Check HTCondor logs in GLIDEINWMS_WMSCOLLECTOR_HOME/condor_local/logs.
-
Verify GLIDEINWMS_WMSCOLLECTOR_HOME/certs/condor_mapfile.
Each DN should map to a user on this system.
The glidein will use the proxy/cert of the Frontend to submit a glidein and the two will need to trust each other. If this is the problem, there will usually be something like this in the SchedLog:
05/05 10:30:11 (pid:21711) OwnerCheck(userschedd) failed in SetAttribute for job 1243.0
- Check the Grid manager log. Note that some configurations put this file in /tmp. This will let you know if there is a problem submitting to grid entry points.
-
Try:
source GLIDEINWMS_WMSCOLLECTOR_HOME/condor.sh condor_q -g condor_q -globus -g
If idle and unsubmitted, the job has not made it to the grid, and there is probably an issue with the condor_mapfile or proxy.
If held, then check the grid manager logs for errors. Also, check condor_gridmanager status in GLIDEINWMS_WMSCOLLECTOR_HOME/condor_local/log/SchedLog
-
If you find an error such as:
Error 7: authentication failed with remote server.
Make sure the proxy/cert is correct. Try the following to make sure the user is authorized to run jobs on the site (You need to have globus-gram-client-tools installed).X509_USER_PROXY=/tmp/x509up_u<UID> globus-job-run -a -r <gatekeeper in Factory config>
-
If you recieve the following error, then check the job logs to see whether this could be a problem with the setup scripts. If the proxy is valid less than 12 hours (eg a Fermilab KCA cert), then the x509_setup script will fail.
Error 17: the job failed when the job manager attempted to run it
- If you expect that the worker nodes are available, check if the glidein is getting periodically held. You can find this information either from the condor_activity log found in the GLIDEINWMS_GFACTORY_HOME/<entry>/log or by querying glideins queue using “condor_q -pool <wms collector> -name <scheddname> <jobid> -format NumGlobusSubmits” Check for error messages in condor_activity logs if your glidein job is being periodically held.
Resource is not registered in user collector.
Symptoms: glidein start running but “condor_status -pool <user collector>” does not show any new resource.Useful Files:
GLIDEINWMS_GFACTORY_HOME/<entry>/log/<glidein jobid>.out
GLIDEINWMS_GFACTORY_HOME/<entry>/log/<glidein jobid>.err
Debugging Steps:
Once the glidein starts running, the glidein startup script downloads condor files and other relevant files from the factories web area. It then does the required checks, generates condor configuration files and starts condor_startd daemon. This condor_startd reports to the user collector as a resource on which the user job is supposed to run. If the glidein job exists and you never see a resource in the User Pool collector, the problem is generally related to bootstrapping the processes on the worker nodes.
If the glidein job has completed, you should be able to look for output and error logs for the glidein job in directory GLIDEINWMS_GFACTORY_HOME/<entry>/log. The files are named are job.<glidein jobid>.out and job.<glidein jobid>.err. Most common cause for the failures is mismatch in the architecture of HTCondor binaries used and that of the worker nodes. You can configure entry points to use different HTCondor binaries. In case HTCondor daemons are crashing, you can browse the logs of HTCondor daemons by using tools available in the /glideinWMS/factory/tools
Other issues that can cause this symptom:
- Factory (or Frontend) Web server down or unreachable
You should see a wget and/or curl error in the Glidein los files. You can test the Factory Web server loading the following URLs (possibly from the Glidein nodes or outside the firewall):
- monitoring pages: http://FACTORY_HOST_NAME/factory/monitor/
- staging area (most files have a hash in the file name): http://FACTORY_HOST_NAME/factory/stage/glidein_startup.sh
- GLIBC incompatibilities:
One possible error that can appear at this point is a problem due to the version of GLIBC:Starting monitoring condor at Fri Jun 18 10:11:27 CDT 2010 (1276873887)
In this case, the version of glibc on the worker node is less than the glibc that HTCondor is using. For instance, this can happen if the Factory is on SL5, but the worker node is SL4. HTCondor has special binaries for glib2.3, so you can re-install/re-compile using these binaries. For advanced users, you can configure multiple tarballs for various architectures in the Factory config.
/usr/local/osg-ce/OSG.DIRS/wn_tmp/glide_rP2945/main/condor/sbin/condor_master: /lib/tls/i686/nosegneg/libc.so.6: version `GLIBC_2.4' not found (required by /usr/local/osg-ce/OSG.DIRS/wn_tmp/glide_rP2945/main/condor/sbin/condor_master)
- Collector authentication issues:
Another error that can happen and cause these symptoms is if authentication is failing. First, verify that the certificates for all services exist and are owned by the proper users. In particular, make sure that the user collector certificate is owned by the user running the user colelctor instance (this can be a non-root user). Another tool to debug errors is to enable the option:CONDOR_DEBUG = D_SECURITY.
You should be able to find errors in the User pool collector logs USER_COLLECTOR/condor_local/log/CollectorLog For instance,03/25/11 15:36:43 authenticate_self_gss: acquiring self credentials failed. Please check your HTCondor configuration file if this is a server process. Or the user environment variable if this is a user process.
Or:globus_sysconfig: File is not owned by current user: /etc/grid-security/glideincert.pem is not owned by current user
- Gridmap issues:
If the problem is not with the user pool resources (collector and/or schedd), a problem could exist with the gridmap on the glidein itself. Symptoms of this could include errors in the startd logs:03/18 13:06:42 (pid:13094) ZKM: successful mapping to anonymous
If this happens, the gridmap file used by the startd (ie the glidein) does not contain the DN for either the user collector or the user submit node. Make sure the information in the <collectors> tag and the <schedds> tags in the frontend.xml are correct and reconfig.
03/18 13:06:42 (pid:13094) PERMISSION DENIED to anonymous@fnpc3061 from host 131.225.67.70 for command 442 (REQUEST_CLAIM), access level DAEMON: reason: DAEMON authorization policy denies IP address 131.225.67.70
03/18 13:07:43 (pid:13094) PERMISSION DENIED to anonymous@fnpc3061 from host 131.225.67.70 for command 442 (REQUEST_CLAIM), access level DAEMON: reason: cached result for DAEMON; see first case for the full reason
User Job does not start on the registered resource
Symptoms:Your job does not start running on the resource created by a running glidein jobs.Useful Files:
Debugging Steps:
On some versions of HTCondor, there is a problem with the swap. Make sure that GLIDEINWMS_USERSCHEDD_HOME/etc/condor_config.local contains RESERVED_SWAP=0
source GLIDEINWMS_USERSCHEDD_HOME/condor.shThe above should return 0.
condor_config_val reserved_swap
Once the glidein starts running on the worker node and successfully starts required HTCondor daemons, condor_startd registers as a resource in the User Pool collector. If your job does not start running on the resource, check that the requirements expressed by the user job can be satisfied by the resource. If not, understand the constraints that are not satisfied and tweak the requirements.
You can get further information on this by running:
source GLIDEINWMS_POOLCOLLECTOR_HOME/condor.shThere will be one "machine" that will act as the monitor and will reject the job due to its own requirements (it is the OWNER). If 1 is rejected by your jobs requirements, check GLIDEINWMS_USERSCHEDD_HOME/condor_local/log/ShadowLog for errors.
condor_q -g -analyze
2.000: Run analysis summary. Of 2 machines,
1 are rejected by your job's requirements
1 reject your job because of their own requirements
0 match but are serving users with a better priority in the pool
0 match but reject the job for unknown reasons
0 match but will not currently preempt their existing job
0 are available to run your job
You can also run the following to get more information about the ClassAds:
condor_q -l
If the job is held, make sure the user schedd is running as root (if getting permission denied). Run "condor_q -analyze" to see what is holding the process.
Finding the user
Symptoms: There are issues and you need to find the user running the jobUseful Files: HTCondor logs, glidein logs
Debugging steps:
When the Frontend sees user jobs in the queue, it requests glideins on behalf of those users. The Frontend provides a proxy (possibly one
shared by multiple members of the VO) that is authorized to submit those glideins to a site. The glideins then report back to the local
HTCondor Collector (User Pool) as slots that are available to run jobs.
Once the user job gets matched to a glidein by the local HTCondor Collector (User Pool),
there are security logs where the identity of the user, retrieved from job attributes, is logged.
This mapping prevents the security problem introduced in pilot-based systems where there is no
authentication of the actual user credentials so that the job is run on a local account.
Because the jobs aren't being run explicitly as the user, it is also not obvious whose job is running at a site.
If you add a x509userproxy in the user job submission it will help w/ identification.
A proxy may also be required for other reasons, such as having the job stage data.
If the glideins have completed
If the glideins have completed, a Factory admin can find the glidein logs in the client logs directory on the Factory. The HTCondor logs are automatically included in the glidein logs sent back to the Factory. GlideinWMS provides tools for viewing these HTCondor logs in glideinWMS/factory/tools/:
- cat_logs.py glidein_log
- cat_MasterLog.py glidein_log
- cat_StartdLog.py glidein_log
- cat_StarterLog.py glidein_log
- cat_StartdHistoryLog.py glidein_log
If the glideins are still running
The user proxy DN is located in the Startd HTCondor logs as the x509UserProxyFQAN. The site admin can access this log on the node under glide_*/log. The location of the glide_* directory may change if multi-glidein or containers are used.
Checking differences in entries configuration
The gfdiff tool can be used to check differences among entries in the xml configuraiton. For example:bash-4.1$ gfdiff --debug --confA=data/automatically_generated.xml --confB=/etc/osg-gfactory/10-cmst1-uscmst2-all.xml --entryA=CMSHTPC_T2_US_Florida_slurm --entryB=CMSHTPC_T2_US_Florida_slurm Checking entry attributes: Key proxy_url(OSG) not found in CMSHTPC_T2_US_Florida_slurm Checking inner xml: GLIDEIN_MaxMemMBs: Key glidein_publish is different: (True vs False) GLIDEIN_MaxMemMBs: Key job_publish is different: (False vs True) CONDOR_ARCH: not present in CMSHTPC_T2_US_Florida_slurm GLIDEIN_Max_Walltime: not present in CMSHTPC_T2_US_Florida_slurm GLIDEIN_SEs: not present in CMSHTPC_T2_US_Florida_slurm